Читайте также:
|
Для того чтобы учесть различные интересы различных пользователей были предложены несколько критериев, рекомендации по которым демонстрируются во фронтенде одновременно. В Таблице 2 показаны названия критериев близости, используемых в системе, и их критерии отбора. Списки полей не приводятся ввиду их неинформативности и большого объема.
Таблица 2. Типы рекомендаций
| Название | Критерий отбора |
| Объекты из других музеев | Поле “Музей” у А и В не совпадает. |
| Объекты с похожими тегами | Множества тегов А и В имеют непустое пересечение. |
| Объекты с похожей датой | Год, вычисленный из поля “Дата” объектов А и В совпадает. |
| Объекты с похожим местом | Поле “Музей” у А и В не совпадает. |
| Похожие объекты из недвижимого наследия | Поле “Класс” объекта В равно “Недвижимое наследие”. |
| Объекты с другим классом | Поле “Класс” у А и В не совпадает. |
| Рекомендации | Поле “Класс” у А и В совпадает. |
Обозначим объекты, для которых производится вычисление баллов близости как А и В, а критерий близости как С. Группировка полей объектов ИС “Открытая Карелия”, изображенных на рисунке 1, представлена в Таблице 3.
Таблица 3. Типы данных для полей объектов
| Тип данных | Поля | Комментарии |
| Массив | Комментарии, изображения, аудио, видео, ссылки, литература, теги | Массив строковых идентификаторов. |
| Текст | Полное и краткое описание | Текст на естественном языке, объемом более пятидесяти слов. |
| Перечисление | Правообладатель, автор, материал, название местоположения, местоположение, местоположение на плане, техника, рубрика, класс, витрина, автор описания | Каждое поле принимает значение из конечного множества строк. |
| Координаты | Координаты | Широта и долгота. |
| Дата | Дата | Информация об эре и годе. |
| Строка | Название, инвентарный номер |
Для полей, для которых типом данных является перечисление, предлагается следующий подход к вычислению баллов близости: если значение сравниваемого поля для обоих объектов равно, то значение баллов близости равно 1, иначе равно 0. Подобная форма сравнения была выбрана по двум причинам. Во-первых, значение функции прямо пропорционально степени сходства значений поля. Во-вторых, зачастую множества значений, соответствующие полям-перечислениям представляют собой наборы сильно отличающихся строк. Например, множество значений поля “Класс” состоит из строк “Музейный предмет”, “Недвижимое наследие”, “Документ”, “Аудио/Видео”, “Персоналия”, “Статья”, “Изобразительный материал”.
Для вычисления количественной степени сходства строковых полей предлагается функция вида:
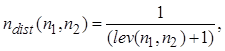
где  и
и  - это сравниваемые значения строковых полей объектов А и В,
- это сравниваемые значения строковых полей объектов А и В,  - функция вычисления расстояния Левенштейна между двумя строками. Расстояние Левенштейна - это минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую. [5] Выбор функции такого вида обусловлен тем, что ее свойства обуславливают понимание сходства названий объектов в смысле баллов близости. Наибольшее значение функции
- функция вычисления расстояния Левенштейна между двумя строками. Расстояние Левенштейна - это минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую. [5] Выбор функции такого вида обусловлен тем, что ее свойства обуславливают понимание сходства названий объектов в смысле баллов близости. Наибольшее значение функции 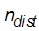 приходится на случай, когда строки полностью совпадают и расстояние Левенштейна равно 0. По мере роста различия между строками и, как следствие, увеличения величины расстояния Левенштейна, значение
приходится на случай, когда строки полностью совпадают и расстояние Левенштейна равно 0. По мере роста различия между строками и, как следствие, увеличения величины расстояния Левенштейна, значение  асимптотически стремится к нулю, что соответствует полностью различным объектам в смысле баллов близости.
асимптотически стремится к нулю, что соответствует полностью различным объектам в смысле баллов близости.
Для определения сходства поля “Тэги” был использован теоретико-множественный подход. Функция сходства была определена следующим образом:

где t1 и t2 – индивидуальные множества тегов объектов А и В, парная вертикальная черта обозначает операцию определения мощности множества пересечения. Использование подобного функционала позволяет напрямую количественно учесть степень сходства двух объектов по множествам тегов в смысле баллов близости – в случае отсутствия общих тегов величина функционала равняется нулю, а в случае наличия общих тегов значение функционала будет прямо пропорционально их наличию. Данная форма функции гарантирует, что величина степени сходства будет прямо пропорциональна величине баллов близости (которые будут иметь строго неотрицательные значения). Недостатком подобной формулировки является игнорирование семантики тегов объектов А и В.
В качестве альтернативы такой функции сходства можно предложить вычисление степени схожести с помощью полнотекстового поиска. Поисковые системы в процессе ранжирования определяют список релевантных объектов по запросу. В качестве запроса можно использовать теги объекта, объединенные дизъюнкцией, в качестве индексации – поля «Название», «Полное описание», «Краткое описание». Такая функция сходства в отличие от предложенной, будет учитывать частоту употребления тегов в описании объекта и исключать широкоупотребляемые теги, таким образом присваивая им меньший вес. Это полезно при нахождении рекомендаций, поскольку частые тэги типа «Карелия» или «Народный» не должны учитываться таким же образом, как и, например, «Риутанвуори».
Для поля “Дата” вычисление количественной степени сходства осуществляется с использованием количественной разницы значений данного поля у обоих объектов, обозначенной через D:

Величина D определяется в зависимости от имеющейся информации о датах для сравниваемых объектов по следующей процедуре:
· если оба объекта имеют информацию о годе (веке) в поле “Дата”, то D вычисляется как разница годов (веков);
· если у одного объекта в поле “Дата” отсутствует информация о годе, но есть информация о веке, в то время как у другого есть оба значения, то разница D вычисляется как разница веков для объектов.
Дата добавления: 2015-10-16; просмотров: 155 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Описание системы | | | Установка и настройка Sphinx |